
Contents
MySQL Binary Log Documentation
How Does MySQL Replication Really Work
Depending on your requirements there are various architectures or ways that you can configure MySQL and MySQL Cluster. Below is just a summary of some of the most frequently used architectures to achieve high availability.
MySQL Master/Slave(s) Replication
MySQL master to slave(s) configuration is the most popular setup. In this design One(1) server acts as the master database and all other server(s) act as slaves.Writes can only occur on the master node by the application
Pros
*Analytic applications can read from the slave(s) without impacting the master
*Backups of the entire database of relatively no impact on the master
*Slaves can be taken offline and sync back to the master without any downtime
Cons
*In the instance of a failure a slave has to be promoted to master to take over its place. No automatic failover
*Downtime and possibly lost of data when a master fails
*All writes also have to be made to the master in a master-slave design
*Each additional slave add some load* to the master since the binary log have to be read and data copied to each slave
*Application might have to be restarted
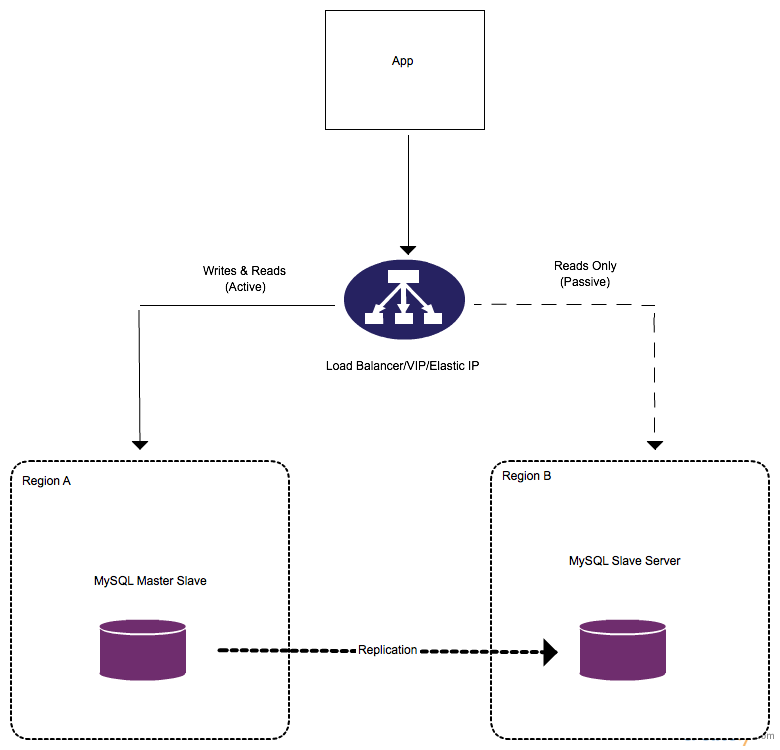
Diagram
In the diagram below the App(Application) talks to a load balancer/VIP/elastic IP. The application(App) is not configured to point directly to the address of the MySQL master node to reduce the configuration changes that might be required within the application (App) in the case of a failure.
Load Balancer – Configured with a fail over load balancing policy/algo(highest priority). In this configuration all requests are sent to a single route or the highest priority(master). Only in the instance of a failure will requests be sent to the alternative route(slave)
Elastic IP – The IP exposed to the application can be configured to point to the master database . When a failure is discovered on the master, the same IP can then be configured to point to the slave database.
VIP – Same as elastic ip above. Can be configured to point to the master/slave as required
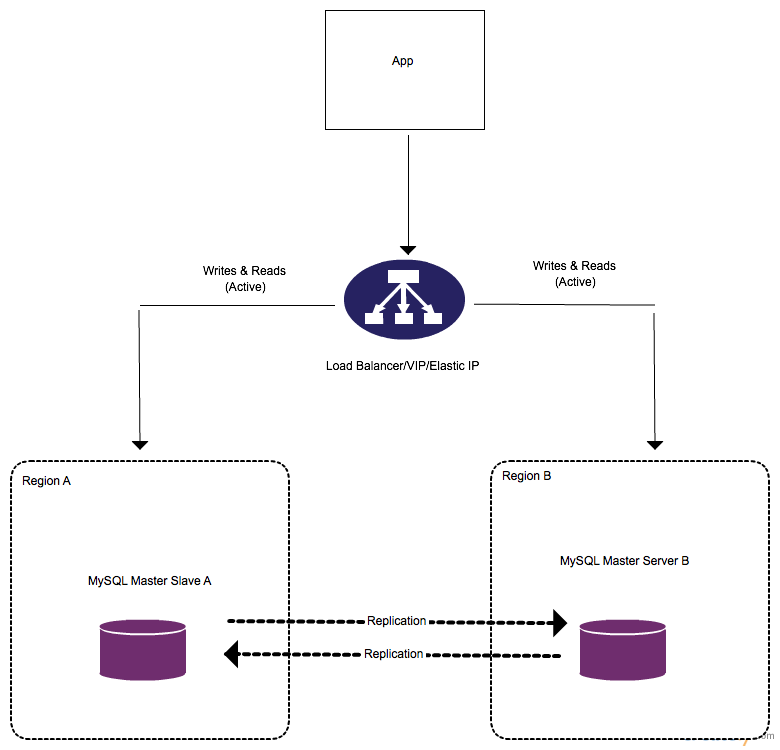
MySQL Master/Master Replication
In a master-master configuration each master is configured as a slave to the other. Writes and reads can occur on both servers
Pros
*Applications can read from both masters
*Distributes write load across both master nodes
*Simple ,automatic and quick failover
Cons
* Loosely consistent
*Not as simple as master-slave to configure and deploy
Diagram
In the diagram below the only significant difference between the master-slave diagram above is that replication(copying data) occurs on both sides of the masters and that both reads & writes can occur on either server.
MySQL Cluster
The new kid in town based on MySQL cluster design. MySQL cluster was developed with high availability and scalability in mind and is the ideal solution to be used for environments that require no downtime, high avalability and horizontal scalability.
See MySQL Cluster 101 for architecture diagram and information related to MySQL
Pros
*(High Avalability)no single point of failure
*Very high throughput
*99.99% uptime
*Auto-Sharding
*Real-Time Responsiveness
*On-Line Operations(Schema changes etc)
*Distributed writes
Cons
Conclusion
There are other options available when looking for high availability architectures for MySQL and any other RDBMS systems such as MariaDB or PostgreSQL You could also look at the use of Shared storage , replication from the storage level and other methods to achieve high availability. Regardless to achieve true high availability a shared nothing architecture would be the recommend option. For the options of using shared storage(NFS)/ replication from the storage level(BLOCK) redundancy is just moved from the database layer to the storage layer.
At the end of the day the database architecture that you decide to use depend on your current and possible future requirements.
This is what successful companies are looking for exactly.
Thanks for the comment and insight David
Detailed Explanation. Thanks
Np. Glad it was helpful. Thanks for commenting.
keep it up
Really high detailed and professional article, thank you very much.
Thank you shrawan & Cybercow
You nailed it Dwayne.It would help me a lot .
Keep going.
Thank you.
Thank you Kiran! Will try to blog more